The idea behind this technique is that once a thread has finished a row, it goes and picks another one to do.
The first method of threading split the image up into however many threads were being used and got each one to work on their own section of the image. However, this led to some threads not doing anything while they were waiting for others to complete.
The trouble with the new method is that while threads are no longer waiting, there are many more total threads created, and there is a fair amount of latency created by that. The upshot of this is that there is less time spent where all cores are being used at the same time.
I conjecture that this would not be the case if the threads were given more work to do. It is the relative time that is important. I only tested this new method using 100 samples per pixel. What I mean by relative time is this: If a thread completes in a shorter time than it takes to create it, it is not worth creating it - this is a high relative creation time; if the time a thread spends working on a task is much greater than the time taken to create it, then it is a low relative time. In the scenario I tested, there was a medium relative time, the original method had a low time, and the one-thread-per-pixel method had a high time.
Here are some graphs to demonstrate how much of the CPU is being used at any one time:
The first method of threading split the image up into however many threads were being used and got each one to work on their own section of the image. However, this led to some threads not doing anything while they were waiting for others to complete.
The trouble with the new method is that while threads are no longer waiting, there are many more total threads created, and there is a fair amount of latency created by that. The upshot of this is that there is less time spent where all cores are being used at the same time.
I conjecture that this would not be the case if the threads were given more work to do. It is the relative time that is important. I only tested this new method using 100 samples per pixel. What I mean by relative time is this: If a thread completes in a shorter time than it takes to create it, it is not worth creating it - this is a high relative creation time; if the time a thread spends working on a task is much greater than the time taken to create it, then it is a low relative time. In the scenario I tested, there was a medium relative time, the original method had a low time, and the one-thread-per-pixel method had a high time.
Here are some graphs to demonstrate how much of the CPU is being used at any one time:
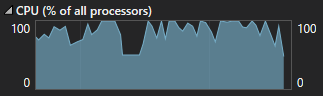
This first graph is representative of the entire program cycle for using "all the threads all the time".
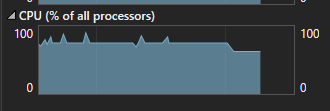
This second graph shows the CPU usage dropping off when the program goes from using 6 threads to 5 threads. Perhaps it is worth noting that one thread was still under 20% complete when this screenshot was taken; this means that one eighth of the image is 5 times easier to render than this thread's eighth. Another thing to consider is that any area of the graph that is not blue can be thought of as wasted.
The time taken to render using the new method was 14 minutes. The time taken using the old method was 26 minutes. That's almost twice as fast! I consider this method a success and will likely use it as a basis to improve upon in the future. The code for it is as follows:
The time taken to render using the new method was 14 minutes. The time taken using the old method was 26 minutes. That's almost twice as fast! I consider this method a success and will likely use it as a basis to improve upon in the future. The code for it is as follows:
int donePixels = 0;
int activeThreads = 0;
int rowCounter = 0;
do
{
while (activeThreads < numThreads)
{
threads.push_back(std::thread(drawRow, rowCounter++, cam, world, &p));
activeThreads++;
}
for (auto &t : threads)
{
if (t.joinable())
{
activeThreads--;
donePixels += nx;
t.join();
}
}
std::cout << donePixels * 100 / (nx * ny) << "% done" << std::endl;
} while (donePixels < nx * ny);
Where drawRow() is defined as follows:
void drawRow(const int row, camera cam, hitable *world, std::vector *p)
{
for (int i = 0; i < nx; i++)
{
vec3 col(0, 0, 0);
for (int s = 0; s < ns; s++)
{
const auto u = float(i + RANDOM) / float(nx);
const auto v = float(row + RANDOM) / float(ny);
ray r = cam.get_ray(u, v, unif, rng);
col += colour(r, world, 0, unif, rng);
}
col /= float(ns);
col = vec3(sqrt(col[0]), sqrt(col[1]), sqrt(col[2]));
const int index = (ny - 1 - row) * nx + i;
(*p)[index] = (*p)[index] + clamp(col, vec3(0, 0, 0), vec3(1, 1, 1));
}
}


 RSS Feed
RSS Feed

